Hey, Make Community! I’m currently working on an automation process that involves retrieving an Excel file from an email, converting it to CSV, and then sending the data from the excel file to monday.com. However, I’ve encountered an issue when the order of columns in the Excel file changes. For instance, if I originally have columns A, B, C, and D, and then a new column is added (A, A’, B, C, D) to file Excel, it causes the data I send to monday.com to be incorrect. Is there any way to handle this situation? I would appreciate any ideas or approaches. Thanks in advance!
The only real way to be sure is to ensure your Excel columns are not modified after building your scenario.
You can do this by locking your header row from modifications.
samliew – request private consultation
Join the unofficial Make Discord server to chat with other makers!
2 Likes
I’m just curious, what technique are you using to convert your Excel attachment to CSV within Make?
Is is an XLS or XLSX format?
In theory, I think if you iterate your rows, you can then aggregate into JSON with a pre-determined Data Structure. Knowing the headers you’re targeting, you can use that with a map() function to get that value from the Excel and write it into the appropriate position in the JSON.
Once your JSON is done, parse it, then aggregate to CSV. The CSV will be in the expected format for downstream use.
2 Likes
Thank you for your reply. I can’t control the excel file format. I receive the email daily from a third party website.
Thank you for your reply.
I just use CloudConvert to convert Excel attachment to CSV. The attachment is in XLSX format.
The new column can be added anywhere between the original columns. Their order will be messed up. How can I use map() to map the data correctly?
This could only work if your columns had headers. Do they have headers or is it just all data?
1 Like
Yes, it does have headers for different data.
It’s complicated, but should work…
After receiving your CSV from CloudConvert, you can:
- Read the first line, determine the position #'s of each header. The result would look something like this, an array of collections where you could get the position number based on the header’s name.

You can use a map() function to get the position number based on name, for example:
map(Array[];Position;Header;email)← This will retrieve the position number for the email Header. - Then, you have an Iterator - JSON Aggregator pair of modules with a filter in-between that filters out the first row.
This JSON Aggregator has a JSON structure similar to what your final CSV should look like.
In this example I only want id, group, and email. I don’t want “bogus” column. These are two number fields and a text field, respectively.
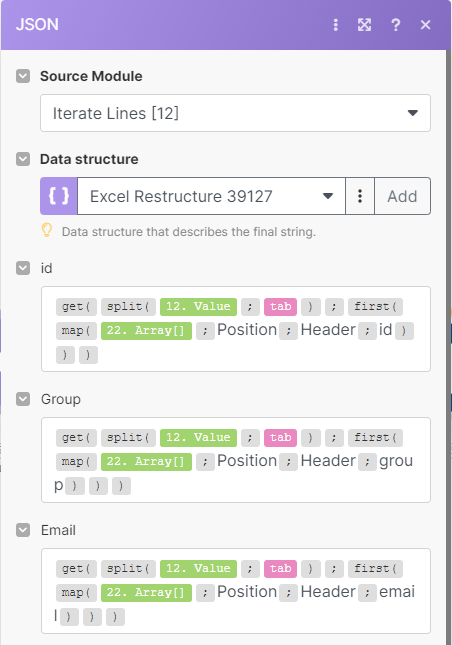
In this Aggregator, for each field, you can use this formula to split the line into an array (I split by {{tab}} because I have a TSV file, but here you should use just a comma), use a get() function to pull the value from the array by its position (the position which is derived from using a map() function against the array created in step 1).
- Finally, Parse that JSON. This will result in multiple bundles, each containing only the id, Email, and Group fields (not the bogus one)

This is multiple bundles of output, 1 for each line of the CSV, so you can either use each bundle/line in the next module, or you can aggregate them again.
Ignore Extra ColX fields.
This should work as long as you know what headers you want ahead of time, and that the source will at least contain those headers, as well as maybe some that you don’t want.
When I get more time I can clean up the blueprint and post it here.
3 Likes
This is awesome. I will bookmark this for future exploration. I went the easy route and made sure my users weren’t adjusting the order of the columns!
2 Likes