Hello all and I am a newbie at this.
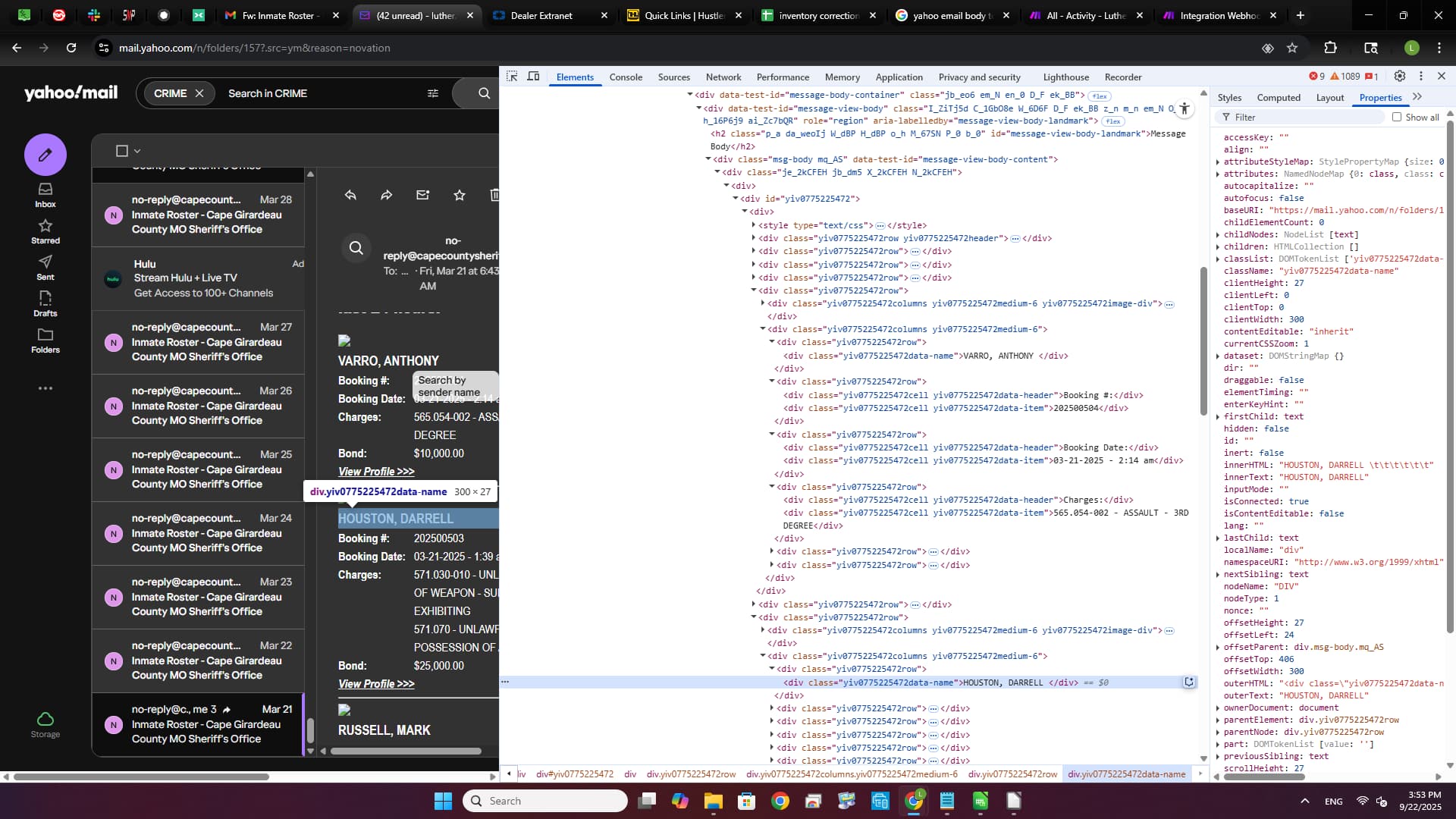
I receive an email from our local sherriffs office, I usually get one a day. I need to figure our on how to extract the email from yahoo data, which I believe is coded differently than the others like gmail and such. I have a webhook established, text parser, and an excel book that is pointing to the correct direction. I think that the information is getting through the webhook, but when it comes to the text parser, that is where I think that it gets lost because I do not know the coding or what to look for. I have attached SS to help illustrate. Thank you all.


Hi @Luther_Haynes and welcome to the Make Community!
It looks like you are trying to extract the text from the HTML you received in the email. If so, use th eHTML to Text tool:

In your screenshot, you’re using the regular expression parser, which is a whole different thing. You can use the HTML content as the data to map.
This is an example with GMail:
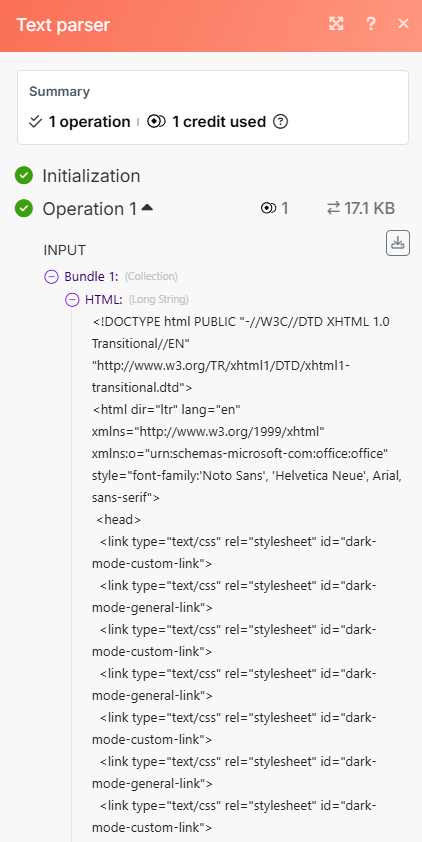

If this is not what you meant, please clarify.
L
Welcome to the Make community!
When reaching out for assistance with extracting text, it would be super helpful if you could share the actual text you’re trying to match. Screenshots of text can be a bit tricky, so if you could copy and paste the text directly here, that would be awesome! It ensures we can run it against test patterns effectively. If there’s any sensitive info, feel free to change it to something fictional yet still valid by keeping the format intact.
Providing clear text examples saves time on both ends and helps us give you the best possible solution. Without proper examples, we might end up playing a guessing game, and nobody wants that as it is a waste of time! You are more likely to get a correct answer faster. So, help us help you by sharing those text snippets.
Please format the example text this way to preserve line breaks and special characters:
Here are some ways to provide text content in a way that it won’t be modified by the forum.
-
Method 1: Type code fence manually —
Add three backticks```in a separate line before and after the content, like this,``` text goes here ``` -
Method 2: Highlight and click the “preformatted text” button in the editor —

-
Method 3: Upload your file and share the public link —
(this method is only recommended for large files exceeding the forum upload limit)
Hope this helps! Let me know if there are any further questions or issues.
— @samliew
P.S.: investing some effort into the tutorials in the Make Academy will save you lots of time and frustration using Make!
2 Likes
Thank you Samliew for the reply. I could post the raw message header information here but that is 34 pages and I have it uploaded in a notepad or txt format. I have also included the pdf version of the email that I look at as well as a copy of the page of the excel file that will be getting the information.
I basically need to extract the name, booking date and the charges.
All of the information contained in the pdfs are basically public information and not restricted since it is broadcasted and not protected by the fourth amendment via the use of a third party.
I use this information for our network of neighborhood watch programs along with other information.
Again, thank you very much for the reply.
RAW MESSAGE HEADER INFORMATION.pdf (151.4 KB)
2025 cape co reports.pdf (34.8 KB)
oster - Cape Girardeau County MO Sheriff’s Office.pdf (236.0 KB)
Thank you for the reply. So I am using the incorrect mod for this. Thank you for expressing that. I have found this inside the raw html data that I want to extract inside the yahoo email:
<div class="ydp9a3055f8yiv8121783184columns ydp9a3055f8yiv8121783184medium-6 ydp9a3055f8yiv8121783184image-div"><img width="200" src="https://capecountysheriff.org/templates/capecountysheriff.org/images/inmates/269e7c42-c78f-47fd-117b-aeb886856a64.jpg" class=""></div>
<div class="ydp9a3055f8yiv8121783184columns ydp9a3055f8yiv8121783184medium-6">
<div class="ydp9a3055f8yiv8121783184row">
<div class="ydp9a3055f8yiv8121783184data-name">VARRO, ANTHONY </div>
</div>
<div class="ydp9a3055f8yiv8121783184row">
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-header">Booking #:</div>
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-item">202500504</div>
</div>
<div class="ydp9a3055f8yiv8121783184row">
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-header">Booking Date:</div>
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-item">03-21-2025 - 2:14 am</div>
</div>
<div class="ydp9a3055f8yiv8121783184row">
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-header">Charges:</div>
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-item">565.054-002 - ASSAULT - 3RD DEGREE</div>
</div>
<div class="ydp9a3055f8yiv8121783184row">
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-header">Bond:</div>
<div class="ydp9a3055f8yiv8121783184cell ydp9a3055f8yiv8121783184data-item">$10,000.00</div>
</div>
I think that the might be the same on every instance of the emails that I need to map, I just cannot figure out on how to get the name, booking date and the charges to show.
OK, so far, I got the html to be placed in the excel cell, the information is getting through in that manner. I just need to get the mapping of the information correct and extracted.
FWIW, I am excited about this. I have not ever done enything like this.
Thank you!
If your emails section allways looks like this, you can use a few options:
-
If you know how to use regular expressaions and you know for sure that the information will always look similar, give a few examples to ChatGPT or another LLM and ask it to extract the information you want. It should come up with a multiline regexp that will match everything for you. Test in on regexp101.com (using the ECMAScript variant) to mkae sure you get what you want, then use that regexp in a text parser and it should work. Make sure not to include the “/” and the flag for multiline input. You configure those flags in the Make module.
Well, I couldn’t help it and I got one and tested it. WIth the sample you provided, this workes on regexp101.com, but I didn’t test in Make:
/<div class="[^"]*data-name[^>]*>([^<]+)<\/div>.*?<div class="[^"]*data-header[^>]*>Booking #:<\/div>\s*<div class="[^"]*data-item[^>]*>(\d+)<\/div>.*?<div class="[^"]*data-header[^>]*>Booking Date:<\/div>\s*<div class="[^"]*data-item[^>]*>(.+?)<\/div>.*?<div class="[^"]*data-header[^>]*>Charges:<\/div>\s*<div class="[^"]*data-item[^>]*>(.+?)<\/div>.*?<div class="[^"]*data-header[^>]*>Bond:<\/div>\s*<div class="[^"]*data-item[^>]*>([^<]+)<\/div>/s
- If that doesn’t work because your input data changes too often, you can use Make’s AI Toolkit to extract text. You just need to get the right prompt.
- If that doesn’t work, you can use the OpenAI or any other LLM’s module to do the same.
Hopefully that helps.
L
P.S. This is the prompt I used with Gemini to produce the regexp: I would like an ECMAScript regexp that matches data that looks like this and extracts the text information. I would like the Name, Booking #, booking date, Charges, and bond. The class IDs and image links will change but the structure remains the same:
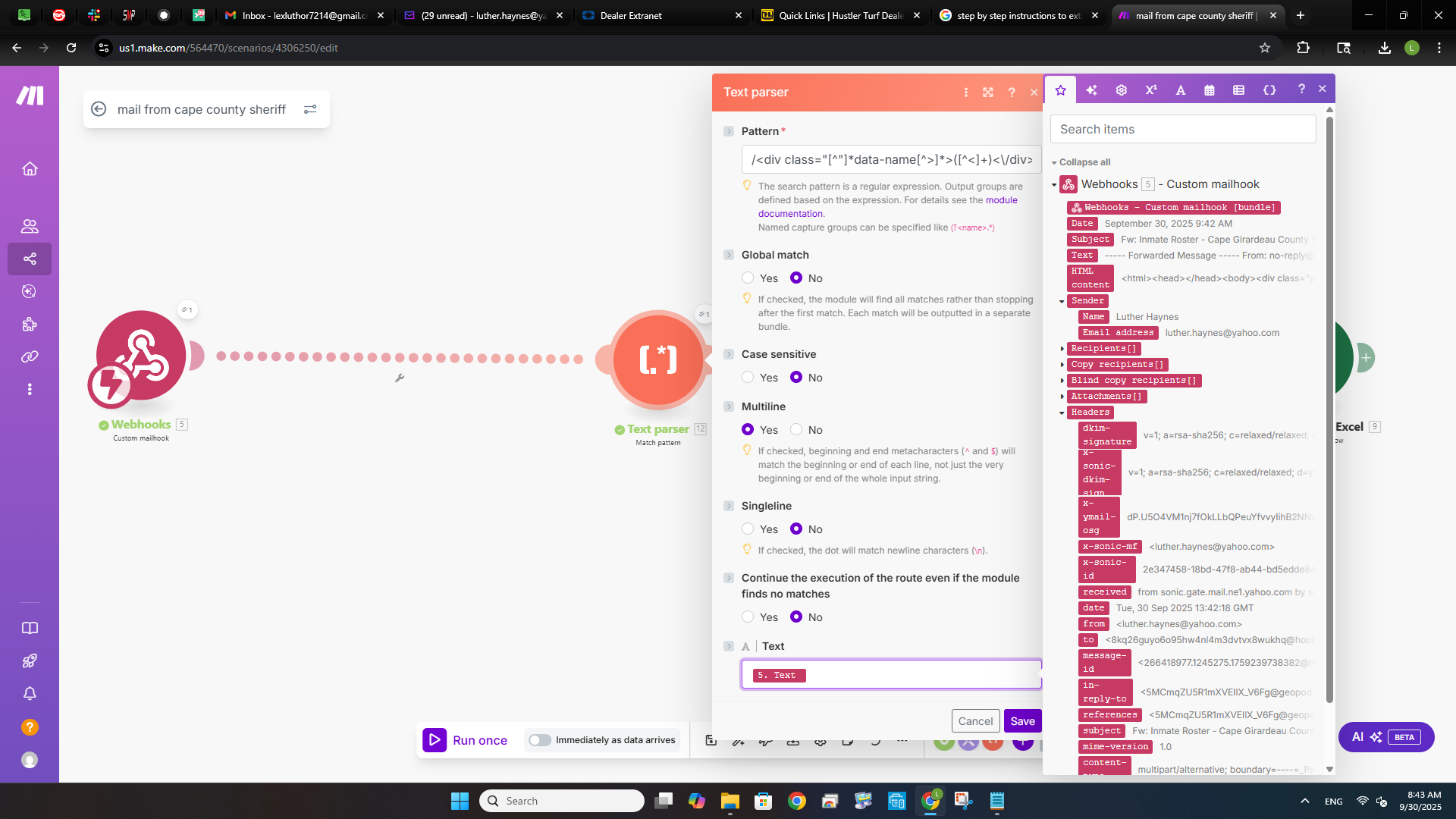
Well, i got something to go through but it is not the correct information that I need, but it is a start. Here are the SS to show what I have have. I think that the parser text is not confiured correctly. I could be wrong, but there is information running about on it.
I have played with the string to not to include the “/” and not and still got the same result. I am not giving up! LOL.




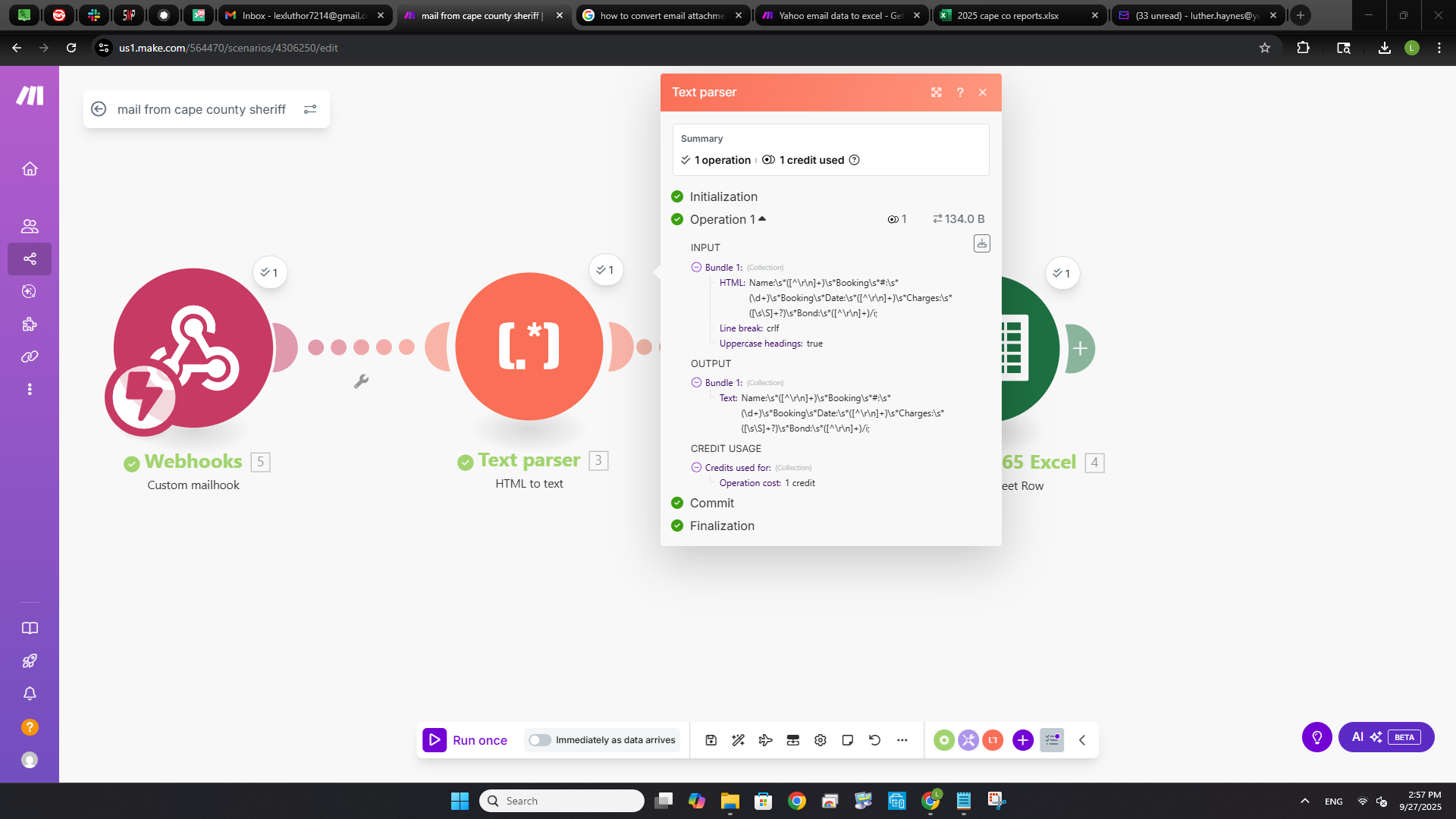
You are not using the correct module. You are using HTML to text. You should be using “Match Pattern”. I think I might not have been clear enough.
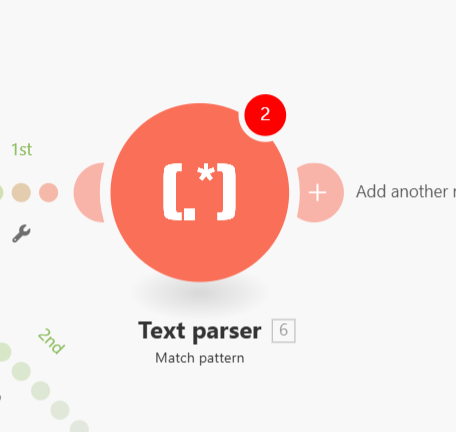
Your pattern goes into the “Pattern” section and your text goes into the “Text” section at the bottom (not shown on the screenshot.
That should give you better results! You might need to play arount with the global/multiline/etc. parameters to match the regex that works correctly.
L

I know that I am close. I still feel like there is something amiss. Have not given up. It is amazing to know that someone that is completely new learning a programming method that I have not even learned about. Still cannot get anything to list on the spreadsheet but this is better than nothing. SS attached and I also have the input of the long string from the text parser match method.
Thank you again for helping me out. You are blessed.
text long string.txt (4.8 KB)



It looks like the Text Parser is not working. Looking at your data, it doesn’t always match what you sent earlier. In particular, in some of the items you sent, the bookings are on two lines instead of one.
At this point, you have choices:
- You can work on creating a regular expression that will work all the time. What this means is that you make it work and whenever you get something that breaks, you need to adjust it. Use https://regex101.com for that.
- Pros: simple to implement and free
- Cons: Can break easily
- Note: You need to split your input and send one booking at a time and probably use an aggregator or a combination of functions.
- Send it to an AI
- Pros: The AIs will be pretty good at catching changes and adapting. If they don’t, you can add that information to your prompt so it knows how to handle the input.
- Cons: It costs money (or extra credits) to use the AI. HOWEVER, if you make it work with Make’s AI Text Extractor by the end of the day (CST), you could enter into the text extractor challenge. Just sayin’.…

- Note: You will need to tell your prompt to output a format that you wnat to work with. It could be CSV (that you could import into Google Sheets), JSON (why you can parse with the JSON tools), or any other format that works well for you.
This regex seems to work for one entry at a time:
/([A-Z]+,\s+[A-Z]+)\s+Booking\s+#:\s+(\d+)\s+Age:\s+(\d+)\s+Release\s+Date:\s+([\d-]+\s+-\s+[\d:]+\s+(?:AM|PM))\s+Booking\s+Date:\s+([\d-]+\s+-\s+[\d:]+\s+(?:AM|PM))\s+Charges:\s+([\s\S]+?)Bond:\s+(\d+)/g
You need to remove the “/” at the beginning and the end. The “g” is for global matching, so remove that and use the global flag in the text parser. If the simple text parser doesn’t work, try the advanced one.
L
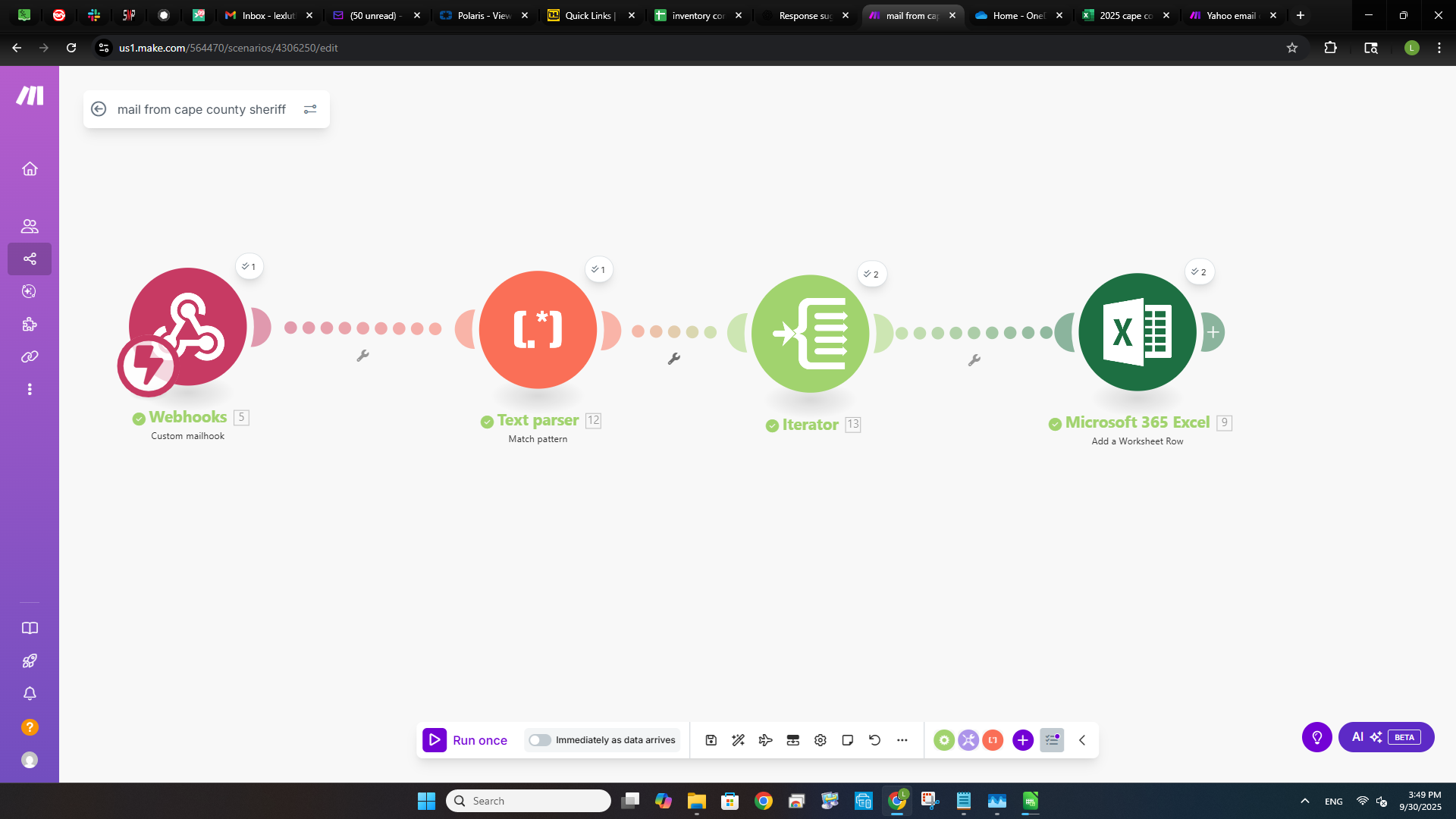
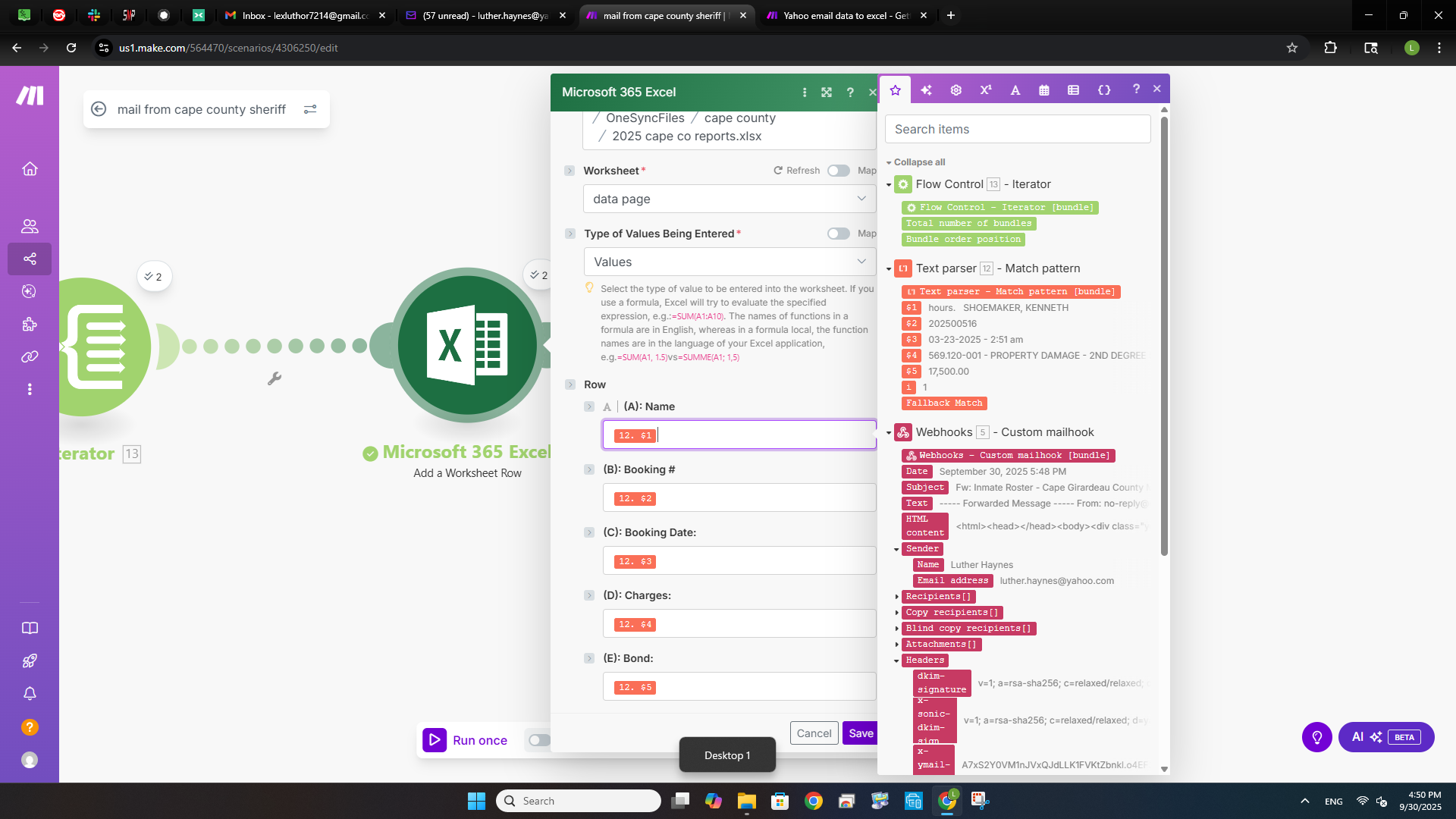
Finally got something that is workable. Here are the screen shots and the data is starting to come through. I had to make sure that I use the regex to help clean it and tune it up when it starts to show an error or the data gets off. I had to put an extra module in to help make it work due to the way that Yahoo email pages are built. Gmail is simplier and more people use those for their examples, I guess that I like the hard stuff.
Thank you L for the advice and the replies, they are helping me. I am still not going to give up hope and learn all that I can. This is some fun stuff to do.
Cheers!




2 Likes