Issue Description
Goal: Extract article content text from HTML received from an RSS feed and save it to a Google Doc.
Scenario Setup:
- RSS Module: Watches RSS feed items and fetches the latest article URL.
- HTTP Module: Makes a GET request to fetch the full HTML content of the article.
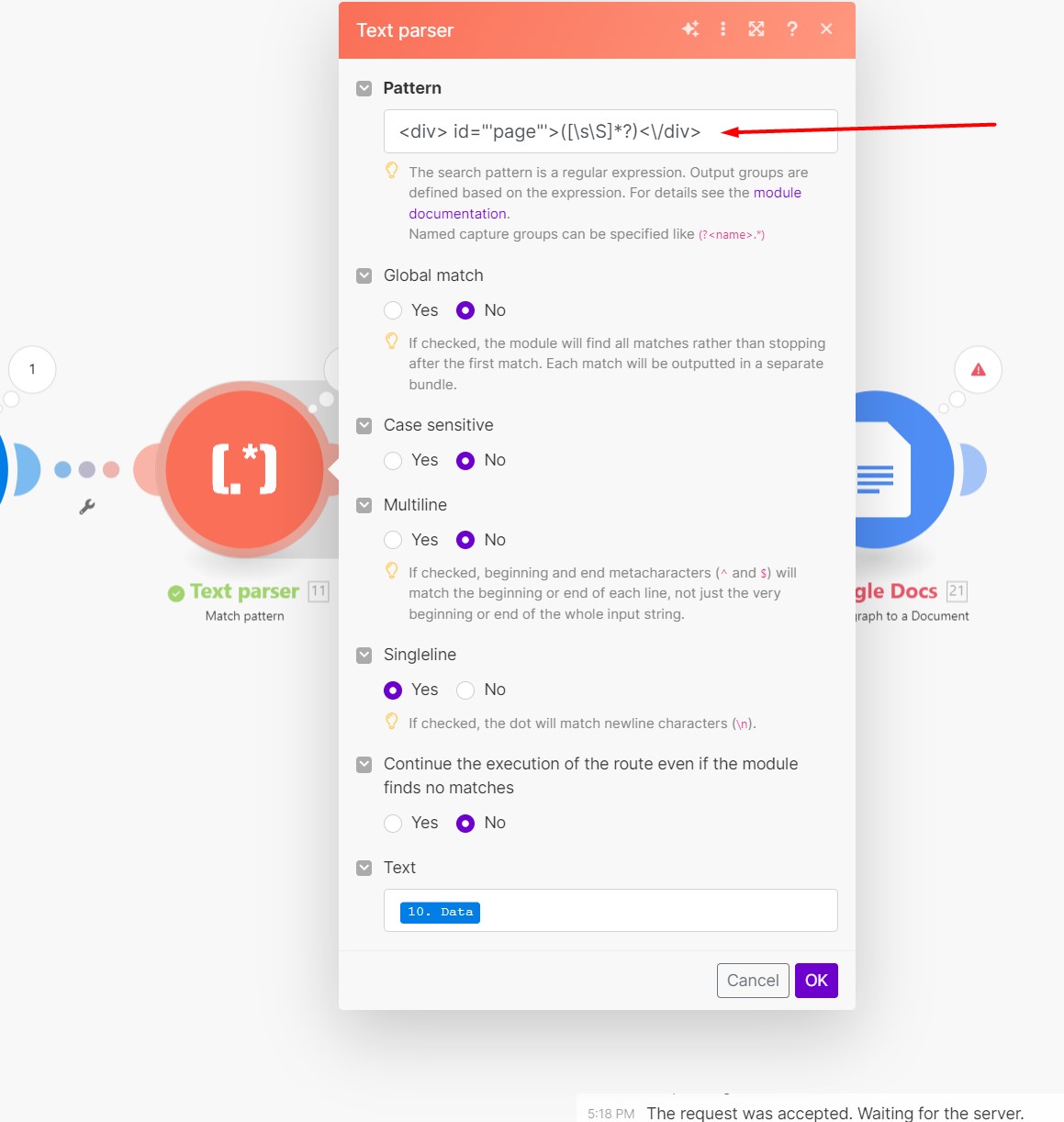
- Text Parser Module: Uses a regex pattern to extract the main content within
<div id="page">...</div> from the HTML response.
- Tools Module (Text Aggregator): Aggregates the extracted text content.
- Google Docs Module: Attempts to save the extracted and aggregated text content to a Google Doc.
Steps Taken:
- RSS Module: Successfully fetches the latest article URL.
- HTTP Module: Successfully fetches the HTML content from the article URL.
- Text Parser Module: Configured with the regex
<div\s+id=["']page["']>([\s\S]*?)<\/div>, but fails to extract the desired text content.
- Tools Module (Text Aggregator): Aggregates the content from the Text Parser module, but does not provide the expected output.
- Google Docs Module: Fails to save the content, resulting in a
BundleValidationError.
Problem:
- The Text Parser module is not extracting the text content from the HTML provided by the HTTP module.
- The Tools module does not produce the expected output to be stored in the Google Doc.
- The Google Docs module shows a
BundleValidationError due to missing content.
Error Message:
BundleValidationError: Validation failed for 2 parameter(s):
Missing value of required parameter 'content'.
Module Configurations and Outputs:
- RSS Module: Correctly fetches the latest article URL.
- HTTP Module: Correctly fetches the HTML content of the article.
- Text Parser Module: Configured to extract content using regex but fails to provide the desired output.
- Tools Module: Aggregates the extracted text but does not provide the expected output.
- Google Docs Module: Fails due to missing content.
Scenario Setup
Scenario Flow:
Scenario Setup (mnt/data/file-o6pYWkusvtoXLeaLATaMEP1W)
Please assist in troubleshooting why the Text Parser module is not extracting the text content from the HTML and why the Tools module is not providing the expected output that can be stored in Google Docs. Any guidance or solution to resolve these issues would be greatly appreciated.
Welcome to the Make community!
1. Screenshots of module fields and filters
Please share screenshots of relevant module fields and filters in question? It would really help other community members to see what you’re looking at.
You can upload images here using the Upload icon in the text editor:

2. Scenario blueprint
Please export the scenario blueprint file to allow others to view the mappings and settings. At the bottom of the scenario editor, you can click on the three dots to find the Export Blueprint menu item.
(Note: Exporting your scenario will not include private information or keys to your connections)
Uploading it here will look like this:
blueprint.json (12.3 KB)
3. And most importantly, Input/Output bundles
Please provide the input and output bundles of the trigger/iterator/aggregator modules by running the scenario (or get from the scenario History tab), then click the white speech bubble on the top-right of each module and select “Download input/output bundles”.
A.
Save each bundle contents in your text editor as a bundle.txt file, and upload it here into this discussion thread.
Uploading them here will look like this:
module-1-output-bundle.txt (12.3 KB)
B.
If you are unable to upload files on this forum, alternatively you can paste the formatted bundles in this manner:
-
Either add three backticks ``` before and after the code, like this:
```
input/output bundle content goes here
```
-
Or use the format code button in the editor:

Providing the input/output bundles will allow others to replicate what is going on in the scenario even if they do not use the external service.
Following these steps will allow others to assist you here. Thanks!
samliew – request private consultation
Join the Make Fans Discord server to chat with other makers!
Looks like your regex is incorrect, since it is not matching anything in the page’s source code.
As you can see here, there are no matches (results) https://regex101.com/r/Gpi4Bj/2
What are you trying to extract?
samliew – request private consultation
Join the Make Fans Discord server to chat with other makers!
If you want the article body, the regex would be
<div class="uni-paragraph article-paragraph"\s+data-component="uni-article-paragraph">\s*(?<article>[\w\W]+?)\s*<\/div>(?=[\w\W]+<\/div>[\w\W]+<div class="uni-blog-article-tags article-tags")
Proof: https://regex101.com/r/Gpi4Bj/4
Then, you can delete the Text Aggregator because you are not using “Global Match”.
These are your two main issues.
samliew – request private consultation
Join the Make Fans Discord server to chat with other makers!
Thank you so much for the assistance its worked
If I may ask for help in the second part of this scenario
Google Sheets Webhook Not Triggering Second Scenario in Make
Description
I have set up a multi-step scenario in Make that involves extracting data from a Google Sheet, processing it, and then updating the Google Sheet based on certain conditions. However, I am facing an issue where the second part of the scenario, which is supposed to be triggered by a webhook from Google Sheets, is not executing as expected.
Scenario Details
blueprint.json (128.0 KB)
First Part of the Scenario:
- RSS Module: Watches for new RSS feed items.
- HTTP Module: Makes a request to fetch data.
- Text Parser: Parses the fetched data to extract specific content.
- Tools Module: Aggregates the parsed text.
- OpenAI Module Summarizes the aggregated text using ChatGPT.
- Google Sheets Module: Adds the summarized text to a Google Sheet.
This part of the scenario works flawlessly and adds a new row to the Google Sheet with the summarized content.
Second Part of the Scenario:
- Google Sheets (Watch Changes): This module is set up to watch for changes in the Google Sheet.
- Router Module: Routes the data based on the “Approval Status” column in the Google Sheet.
- Path 1 (Yes): If “Approval Status” is “Yes”, it posts the content to X, Facebook, and LinkedIn.
- Path 2 (No): If “Approval Status” is “No”, it sends the content to ChatGPT for further summarization and then updates the Google Sheet with the new summary.
Problem Encountered
When I change the “Approval Status” in the Google Sheet to “No”, the webhook is supposed to trigger the second part of the scenario. However, this is not happening. Here are the specific steps I have taken and the configurations I have set up:
-
Webhook Configuration:
- I have created a webhook in the Google Sheets add-on in Make.
- The webhook is correctly linked to the Google Sheet and set to trigger on changes.
Here the link to it
Edelman content - Google Sheets
-
Google Sheets Watch Changes Module:
- This module is set as the first module in the second part of the scenario.
- The webhook URL is configured correctly.
- The trigger event is set to “On change”.
-
Router Configuration:
- Path 1 is configured to filter where “Approval Status” equals “Yes”.
- Path 2 is configured to filter where “Approval Status” equals “No”.
Request for Assistance
Could you please help me identify why the webhook is not triggering the second part of my scenario? Any insights or suggestions to resolve this issue would be greatly appreciated.
No problem, glad I could help!
1. If you have another new question in the future, please start a new thread. This makes it easier for others with the same problem to search for the answers to specific questions, and you are more likely to receive help since newer questions are monitored closely.
2. The Make Community guidelines encourages users to try to mark helpful replies as solutions to help keep the Community organized.
This marks the topic as solved, so that:
- others can save time when catching up with the latest activity here, and
- allows others to quickly jump to the solution if they come across the same problem
To do this, simply click the checkbox at the bottom of the post that answers your question:

3. Don’t forget to like and bookmark this topic so you can get back to it easily in future!
4. Do join the unofficial Make Discord server for live chat and video assistance
samliew – request private consultation
Join the Make Fans Discord server to chat with other makers!