I am new to Make.com and have been playing around with creating a newsletter aggregator. I have created the flow for pulling the right emails, downloading them as PDFs, and uploading them to drive. However, downloading the newly created PDFs and getting them into ChatGPT for summarization and eventually publishing in a new google doc or otherwise is where I run into issues.
Full Flow, issues start at Iterator. See below.
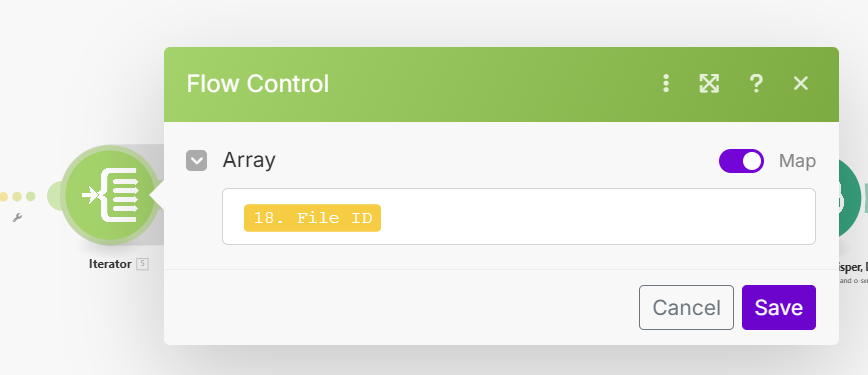
- Problems start at the Iterator. I currently have it pulling “File ID” in the array pulling form the previous file search google drive node, but I am not sure that is correct.
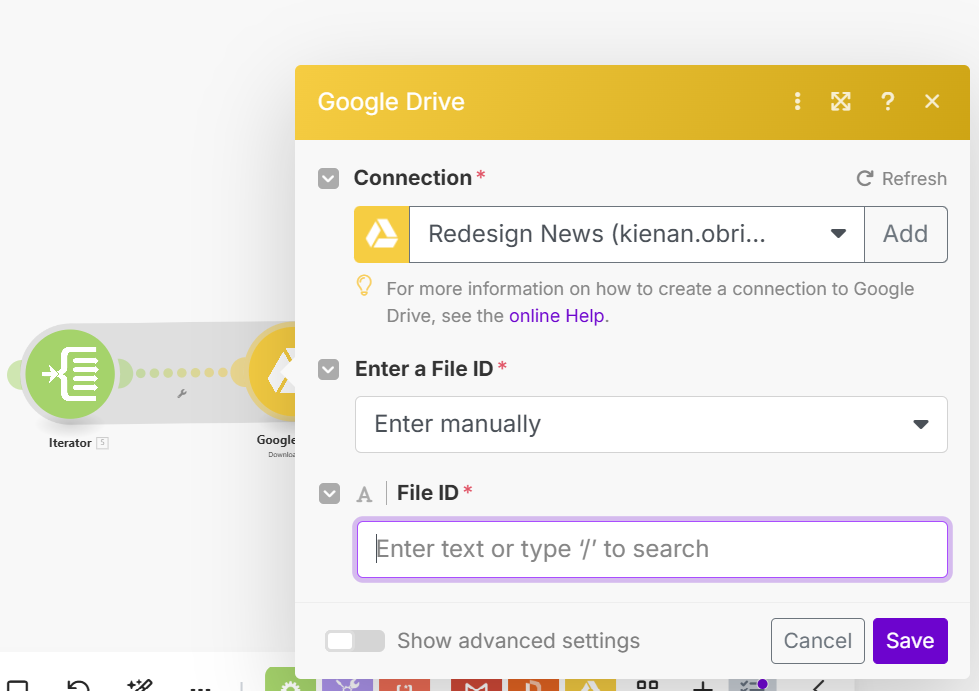
- My next issue is in the download tab. I am not sure what to point it to given the purpose of the node normally is to download a single file. I should also note I can’t seem to save any field I select in the File ID field.
- We then have the aggregator. I have it pointing at the iterator, but I am not sure what I am supposed to be aggregating from it.
- I also do not know what to put in the final ChatGPT node in order to summarize the files we’ve sent it.
Hi @Redesign and welcome to the Make Community!
So let’s see if I can give answers to all your question.
- The aggregator needs to work with a module that produces more than one bundle. The google drive already returns multiple bundles so you don’t need another iterator.
- The file ID is the one that comes out of of the search drive module.
- With the iterator out of the way you can point it to the search module
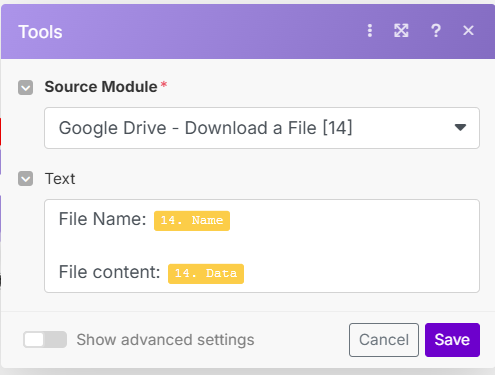
- Each download file module has a Data field in them. That field contains the content of all the files you downloaded. If you store that in the aggregator, you can take that data and send it to your ChatGPT module.
Hope that helps. Ask more questions if you need more details,
L
Got it! I think that is a start. I updated the workflow to the below
The problem now is that I am not sure how I am getting the “aggregated” bundled files uploaded into chatgpt. Here is how I have tried to set it up
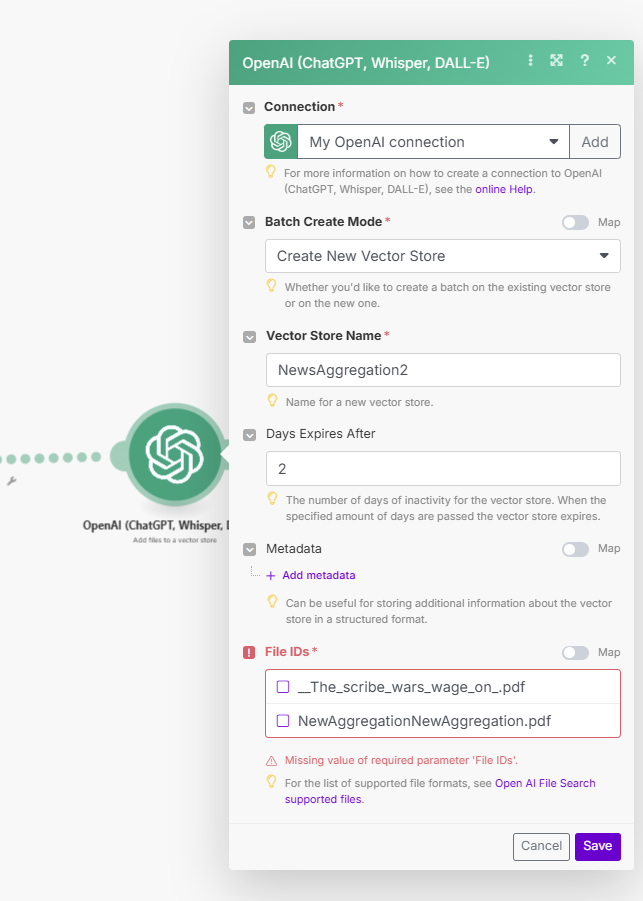
I then want to make sure those uploaded files find their way to a vector database
The problem is I don’t think my upload node is pulling all the content of those pdf files that the search for files node is identifying and the aggregator is pulling together. Which is in turn creating porblems getting it into a vector store.
Any advice for this part of the process? Keep in mind there are about 6 files in this folder that I want aggregated
Hi,
When you do the aggregation, you end up with one bundle that has all the files in it as an array. Take a look at the output bundle to see what I mean (that’s the number that appears after a note has run):
The “2. Data” variable contains the "content of the file. So if your file contains only text, you could do something like this:
- Instead of the aggregator, use a text aggregator
- Use the text aggregator to build the equivalent of what you would copy paste in your ChatGPT prompt
- Use the “text” of the aggregator as part of your ChatGPT prompt
However, if you have documents (PDFs it seems in this case) then you would need to attatch each document to your ChatGPT prompt using the “2. Name” field or the URL of the file (I’m not sure which one the assistant API needs). Then your assistant would work correctly.
L
P.S. Note that the Assistants API will be deprecated in a year. I’m not sure the new API (the Responses API) has been fuly integrated in Make yet. Keep an eye out so you can update your call once it’s ready.
They are indeed PDFs that I want to upload into ChatGPT ideally. But I want to upload multiple PDFs that will be in the folder, not just one URL for one file. Is there someway to get it so it can repeat the process and upload each file in the folder?
If you use the Array Aggregator instead of the Text Aggregator and use the URL of the file instead of the file name, you will get an array of URLs. I’m not sure what format the Assistant/Responses API accepts as input for files but if it accepts an array, you can give the array as nput and it will work. Otherwise you might have to add the files to the list one at a time.
I would test but the servers are down right now so I can’t check.
L
Hi @Redesign Welcome to the community!
Refer to this solution Passing two documents into a gpt module - #7 by Prem_Patel which will help you in your case.
Best,
@Prem_Patel
1 Like