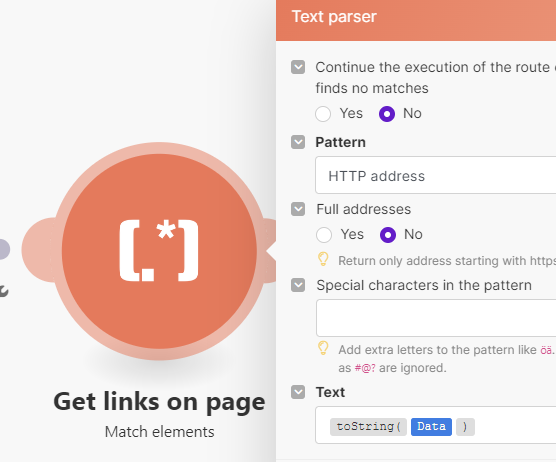
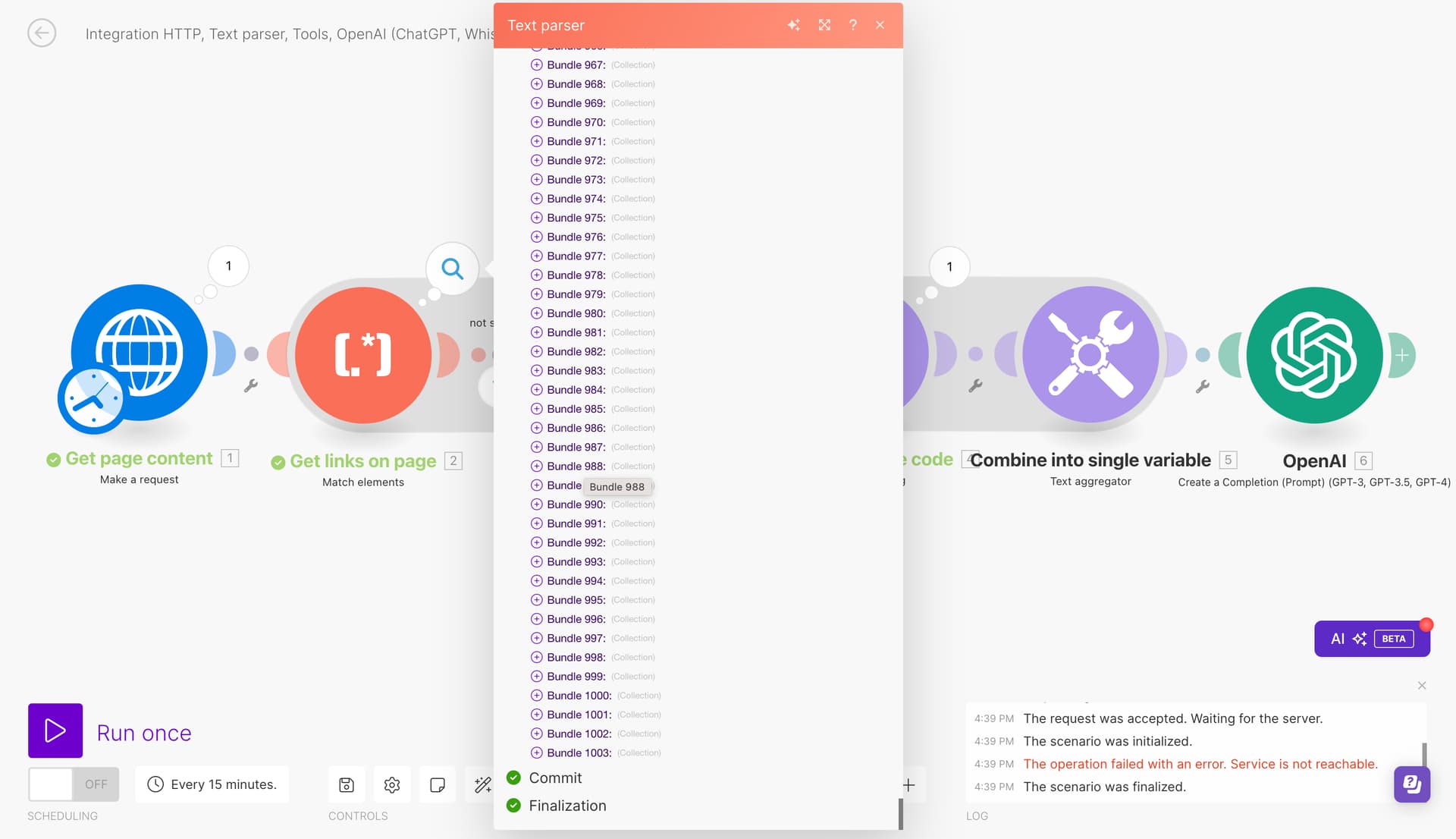
Click to Expand Module Export Code
JSON - Copy and Paste this directly in the scenario editor
{"subflows":[{"flow":[{"id":39,"module":"http:ActionSendData","version":3,"parameters":{"handleErrors":true,"useNewZLibDeCompress":true},"mapper":{"url":"https://www.make.com/en","serializeUrl":false,"method":"get","headers":[],"qs":[],"bodyType":"","parseResponse":false,"authUser":"","authPass":"","timeout":"","shareCookies":false,"ca":"","rejectUnauthorized":true,"followRedirect":true,"useQuerystring":false,"gzip":true,"useMtls":false,"followAllRedirects":false},"metadata":{"designer":{"x":-8,"y":-1522,"name":"Get page content"},"restore":{"expect":{"method":{"mode":"chose","label":"GET"},"headers":{"mode":"chose","collapsed":true},"qs":{"mode":"chose","collapsed":true},"bodyType":{"collapsed":true,"label":"Empty"},"parseResponse":{"collapsed":true}}},"parameters":[{"name":"handleErrors","type":"boolean","label":"Evaluate all states as errors (except for 2xx and 3xx )","required":true},{"name":"useNewZLibDeCompress","type":"hidden"}]}},{"id":40,"module":"regexp:GetElementsFromText","version":1,"parameters":{"continueWhenNoRes":false},"mapper":{"pattern":"##http_urls","text":"{{toString(39.data)}}","requireProtocol":false,"specialCharsPattern":""},"metadata":{"designer":{"x":238,"y":-1519,"name":"Get links on page"},"restore":{"expect":{"pattern":{"label":"HTTP address"}}},"parameters":[{"name":"continueWhenNoRes","type":"boolean","label":"Continue the execution of the route even if the module finds no matches","required":true}],"interface":[{"name":"match","label":"Match","type":"any"}]}},{"id":42,"module":"http:ActionSendData","version":3,"parameters":{"handleErrors":true,"useNewZLibDeCompress":true},"filter":{"name":"not self link","conditions":[[{"a":"{{40.match}}","o":"text:notequal:ci","b":"https://www.make.com/en"}]]},"mapper":{"url":"{{40.match}}","serializeUrl":false,"method":"get","headers":[],"qs":[],"bodyType":"","parseResponse":false,"authUser":"","authPass":"","timeout":"","shareCookies":false,"ca":"","rejectUnauthorized":true,"followRedirect":true,"useQuerystring":false,"gzip":true,"useMtls":false,"followAllRedirects":false},"metadata":{"designer":{"x":537,"y":-1520,"name":"Get linked page content"},"restore":{"expect":{"method":{"mode":"chose","label":"GET"},"headers":{"mode":"chose"},"qs":{"mode":"chose"},"bodyType":{"label":"Empty"}}},"parameters":[{"name":"handleErrors","type":"boolean","label":"Evaluate all states as errors (except for 2xx and 3xx )","required":true},{"name":"useNewZLibDeCompress","type":"hidden"}]}},{"id":46,"module":"util:ComposeTransformer","version":1,"parameters":{},"mapper":{"value":"{{toString(42.data)}}"},"metadata":{"designer":{"x":784,"y":-1521,"name":"Get page source code"},"restore":{},"expect":[{"name":"value","type":"text","label":"Text"}]}},{"id":47,"module":"util:TextAggregator","version":1,"parameters":{"rowSeparator":"\n","feeder":40},"mapper":{"value":"{{46.value}}{{newline}}"},"metadata":{"designer":{"x":1037,"y":-1520,"name":"Combine into single variable"},"restore":{"parameters":{"rowSeparator":{"label":"New row"}},"extra":{"feeder":{"label":"Get links on page - Match elements"}}},"parameters":[{"name":"rowSeparator","type":"select","label":"Row separator","validate":{"enum":["\n","\t","other"]}}],"advanced":true}},{"id":48,"module":"openai-gpt-3:CreateCompletion","version":1,"parameters":{"__IMTCONN__":107818},"mapper":{"select":"chat","max_tokens":"128000","temperature":"1","top_p":"1","n_completions":"1","response_format":"text","model":"gpt-4-turbo","messages":[{"role":"user","content":"Analyze the following content and provide a summary:\n\n{{47.text}}"}]},"metadata":{"designer":{"x":1283,"y":-1519,"name":"OpenAI"},"restore":{"parameters":{"__IMTCONN__":{"label":"OpenAI","data":{"scoped":"true","connection":"openai-gpt-3"}}},"expect":{"select":{"label":"Create a Chat Completion (GPT Models)"},"logit_bias":{"mode":"chose"},"response_format":{"mode":"chose","label":"Text"},"stop":{"mode":"chose"},"additionalParameters":{"mode":"chose"},"model":{"mode":"chose","label":"gpt-4-turbo (system)"},"messages":{"mode":"chose","items":[{"role":{"mode":"chose","label":"User"}}]}}},"parameters":[{"name":"__IMTCONN__","type":"account:openai-gpt-3","label":"Connection","required":true}]}}]}],"metadata":{"version":1}}