Hello, community!
We are facing a critical issue where our scenario starts looping uncontrollably after we introduced Text Parser modules. We need guidance on how to manage data bundles efficiently in this context.
- Brief Description of Scenario and Goal:
Our scenario is a complex sequence for automatically processing documents and forms (starting with a Webhook).
Goal: Receive form data, including text and photos/files, process them, and extract key data points.
Logic:
Webhook receives data (1 Bundle).
PDF.co transforms PDFs into PNGs.
Google Cloud Vision performs OCR on images.
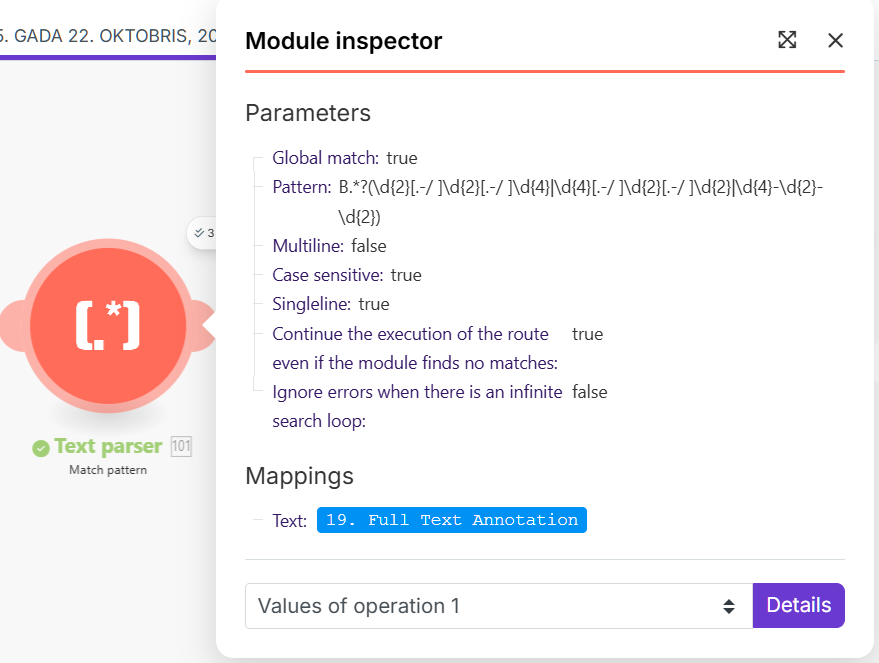
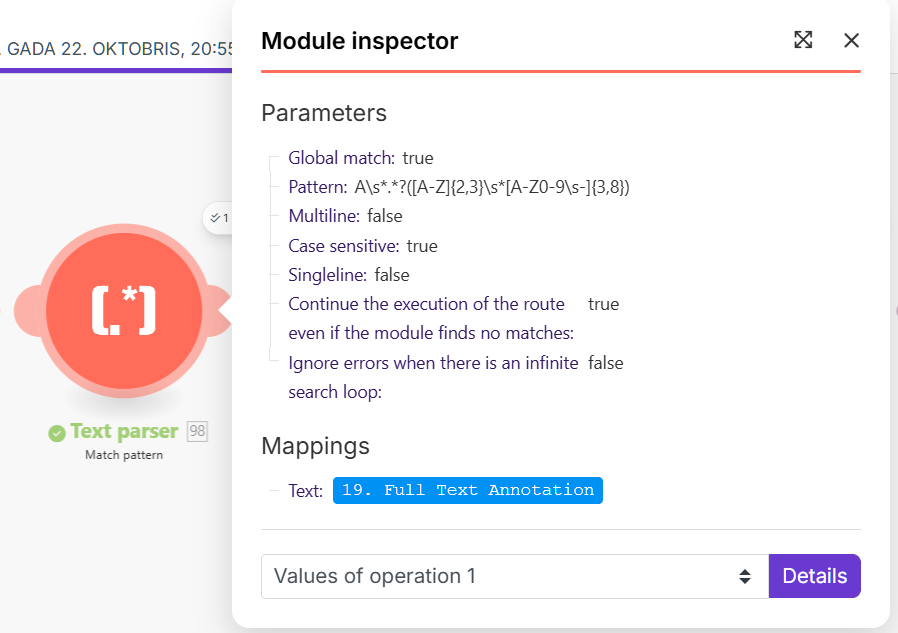
Three separate Text Parser modules follow to extract three different, specific values (e.g., Name, Date, ID) from the OCR result.
- Symptom and Looping Issue:
The scenario works correctly and executes once for each incoming Webhook before the Text Parsers are added.
After implementing the three Text Parser modules, the scenario begins repeatedly executing all subsequent modules (PDF.co, Google Cloud Vision, etc.) in a massive, uncontrolled loop. This continues until the operations are complete, costing many operations. Removing the Text Parsers resolves the issue immediately.
- Question:
We assume that each of our three Text Parser modules generates an individual output bundle, and these multiple bundles then force the rest of the script to execute repeatedly, causing the loop.
How can we reliably collapse all the extracted values (from the three Text Parsers) back into a single bundle to ensure that all subsequent modules are executed only once?
Please suggest the simplest and most efficient method for solving this data flow (bundling) issue within a single script.
CRITICAL: We will attach screenshots of our scenario map for better context!
Thank you for your help!