I have a recurring issue with various scenarios and I wanted to generalize it and see if others with conceptually similar issues have found a solution.
The problem arises in cases where I want to search multiple apps for existing records relating to an incoming payload (say, to see if the client who just booked a new appointment already has a record in Google Sheets and/or ClickUp).
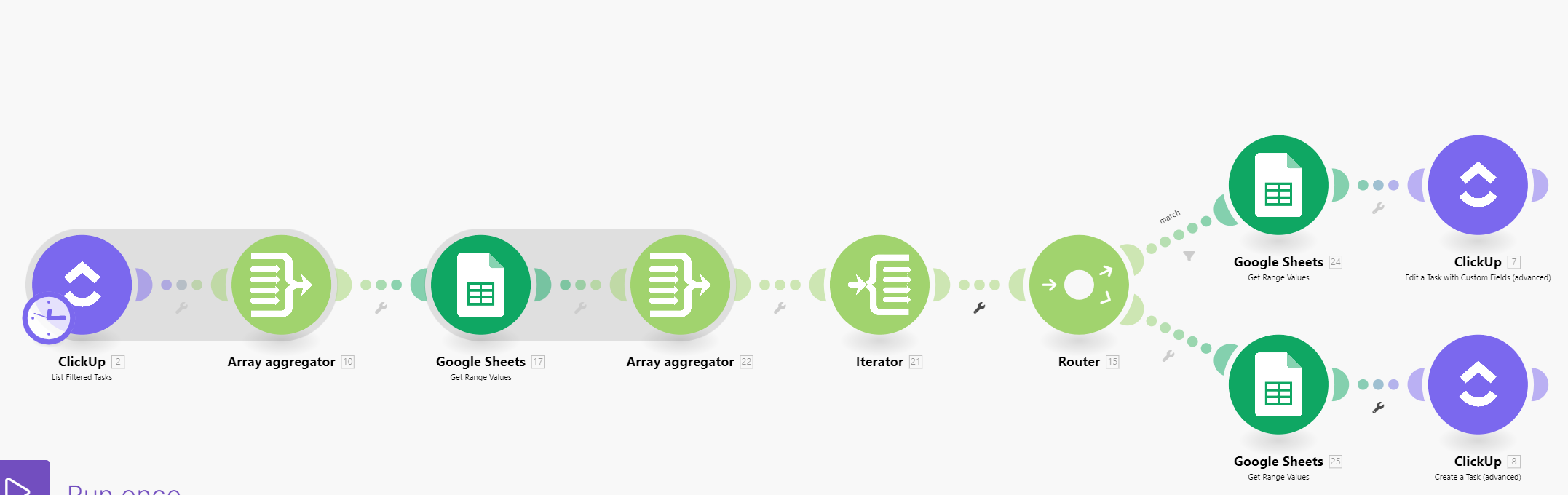
I list the existing records in app #1 (say, Search Rows in Sheets), aggregate a matching parameter (say, email) and then iterate through the results. I then run all those bundles through a router with filtered routes to see if they match the parameter (email) on the new payload that triggered the scenario. If they do, I update the existing record with data from the payload. If they don’t, I create a new record.
Now, in either case, I want to check for an existing record in app #2 (say, ClickUp). Since Make doesn’t have a converger module (the opposite of a router, though I think they used to), I have to duplicate all the following steps for each route. For instance, after creating a new Sheets row, I have to list, aggregate, iterate, route, filter, and update or create ClickUp task. Then I have to copy all that down to the other route so it also happens after updating a Sheets row.
Now here’s the problem: It would seem more elegant to search both apps’ existing records, then route the bundles through a four-way router that functions like an ELSIF: route 1 would pass bundles that matched in both app 1 and app 2, and subsequent modules would update both records; those that fail go on to route 2, which passes those that match app 1, which updates that record and creates a record for app 2; those that fail go to route 3, which passes those that match app 2, updates that record and creates a record for app 1; and those that fail go to route 4, the fallback route, which creates records in both apps.
The problem is that if you list the records in both apps on the same route, you get compounding numbers of operations, with each output bundle from app 1 module triggering a search operation on app 2 module, thus using ops equal to the product of the numbers of records in each app. With lots or records or more than two apps, it can run easily to five figures and blow your usage in one go, unless you force stop is, as here:

So I think the only way is to create duplicate routes. Less elegant, but should solve the problem. Any ideas? Will report back once I’ve built the ugly duplicative version.