Hi folks,
I’m trying to build a scenario that pulls specific records from Airtable, groups them, and then for each group generates three aggregated lists of like values - like this:
[
{
“sales_rep”: “SALES REP 1 NAME”,
“inventory_numbers”: [“3283E”, “3310E”],
“market_regions”: [“NATIONWIDE”, “NATIONWIDE”],
“list_prices”: [15750, 23500]
},
{
“sales_rep”: “SALES REP 2 NAME”,
“inventory_numbers”: [“9999”],
“market_regions”: [“WEST”],
“list_prices”: [65000]
}
]
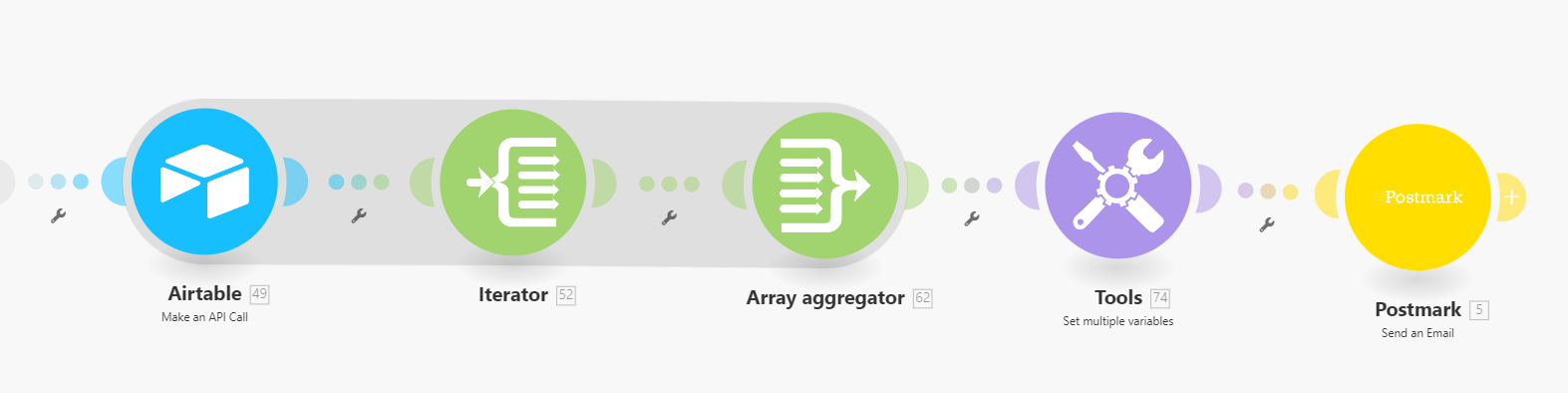
The closest I’ve come so far is to have a sequence of iterators and text aggregators, one for each set of values:
But as you can see, the iterators double the number of operations each time, even though they’re all three pulling from the airtable api call module.
I’ve attached the blueprint and output bundles for the first three modules; the additional operations from the 2nd and 3rd iterators are just duplicates and then quadruplicates, respectively.
What am I missing?
Thank you for your attention,
Shawn
airtable-output.txt (78.3 KB)
iterator1-output.txt (66.4 KB)
textag1-output.txt (174 Bytes)
Expired Listings Notifications (copy).blueprint.json (30.6 KB)
Heyy @shawn_kellar iterator will iterate the array you have mapped but if the previous module before iterator returns 2 bundles, it will iterator 2 times means 2 operations and goes upto n numbers if previous module returns n no. of bundles. So, you have to make sure that your text aggregator returns only 1 bundle if you don’t want to have repeated numbers of operations.
I hope this helps!
Best,
@Prem_Patel
Hi @Prem_Patel, thank you for your response. Now I understand why the doubling occurs, but I think I started with the wrong questions, because I still don’t understand how to do what I’m trying to do:
The Airtable module pulls a bundle consisting a collection with an array of records according to the filter set in the module settings:
From here, I am trying to split the bundle by SALESP - which in this case would result in 2 bundles - and then aggregate each of the three variables into separate lists, which in this case would look like this:
Salesperson: CURREN ANGLIN
Inventory #’s: 9999
Markets: WEST
List prices: 65000
(Because Curren’s bundle only has one set of variables, but Zane’s has three:)
Salesperson: ZANE KELLAR
Inventory #’s: 3283E,3310E,3289P
Markets: NATIONWIDE,NATIONWIDE,NATIONWIDE
List prices: 15750,23500,27500
Ideally, the lists would be separated by a new line rather than a comma; I set them up this way to make the configuration easier to see visually.
The way that I have it set up in the screenshot above does that, but I get the doubling problem.
I’ve tried using an array aggregator both before and after the iterator, and nothing so far has worked.
So the question I have now is: how do I get this scenario to do what I want it to do?
Ah! I figured it out!
The iterator pulls the fields out of the collections and makes them available for the array aggregator.
The array aggregator bundles them according to sales rep.
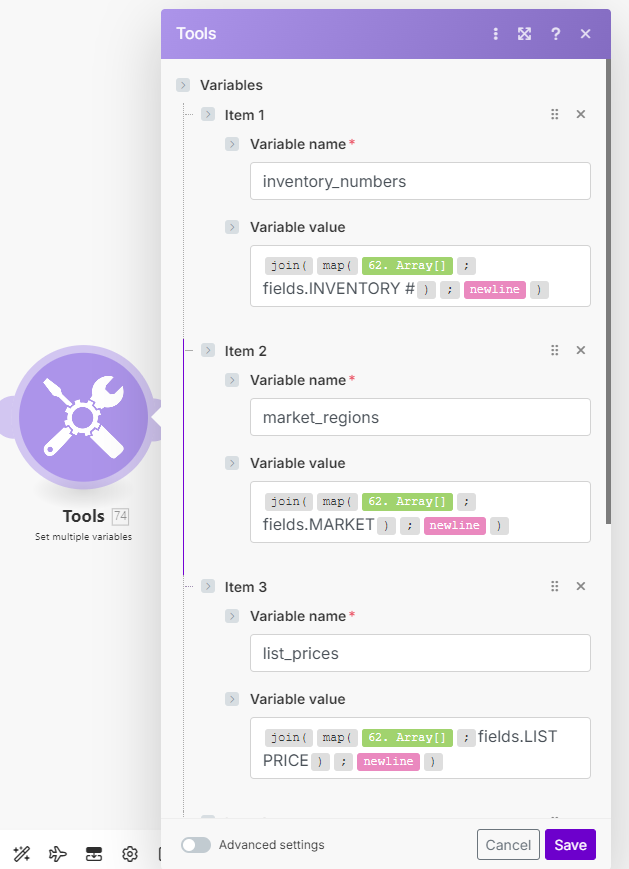
Then using a regex that took a while to nail down, set multiple variables:
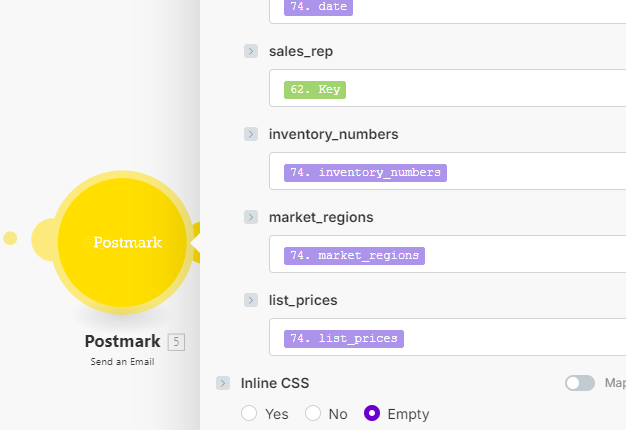
Then those variables were available to plug right into the postmark template:
You can use group by field in the array aggregator after enabling advanced option toggle to get those bundles specific to those salesperson.
Best,
@Prem_Patel