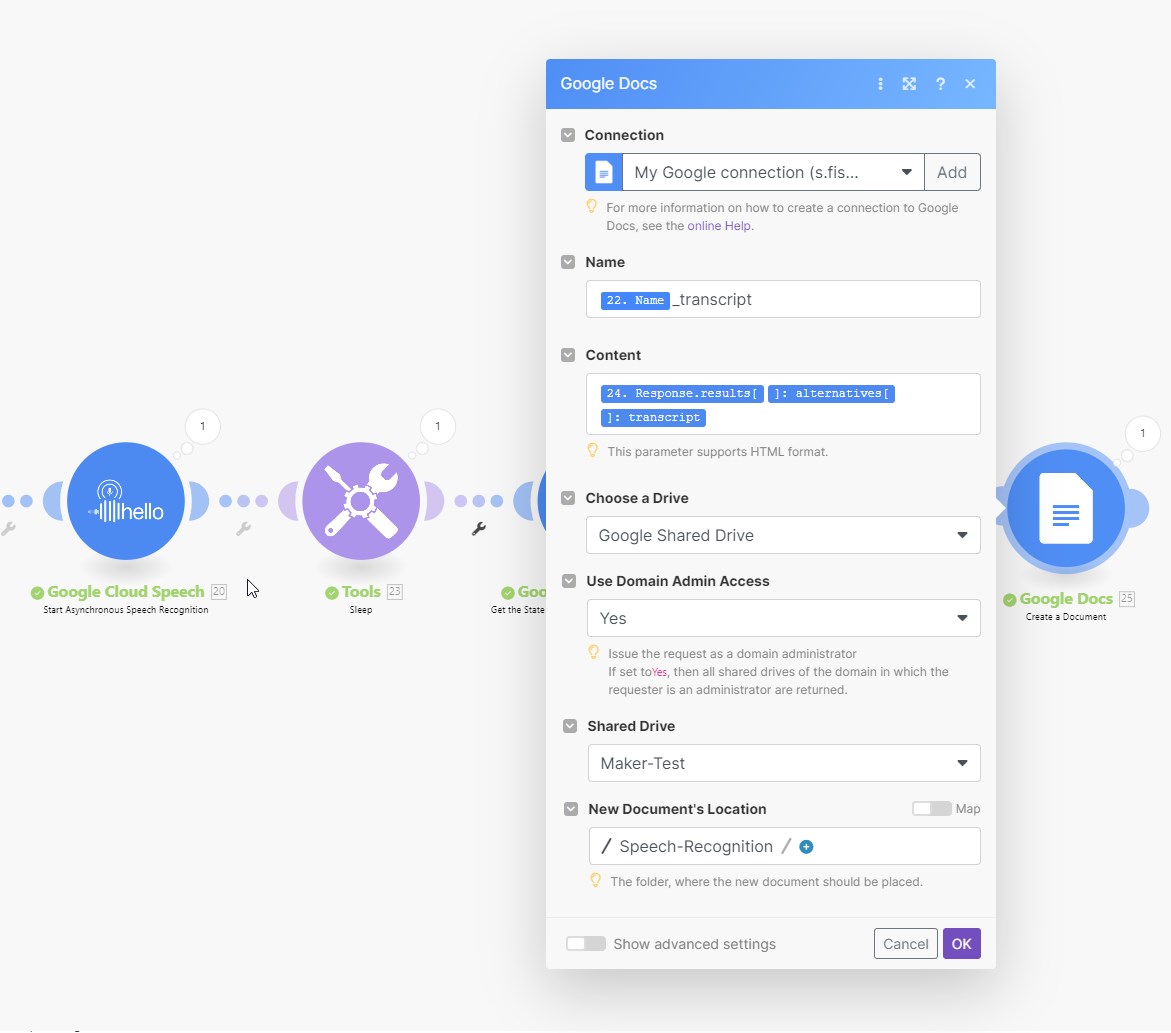
Hello I would like to use Google Cloud Speech to automatically transcribe MP3 voice recordings into German.
With the template “Transcribe new short mp3 files from Google Drive with Google Cloud Speech” I managed to do this, but only with MP3s shorter than 1 minute.
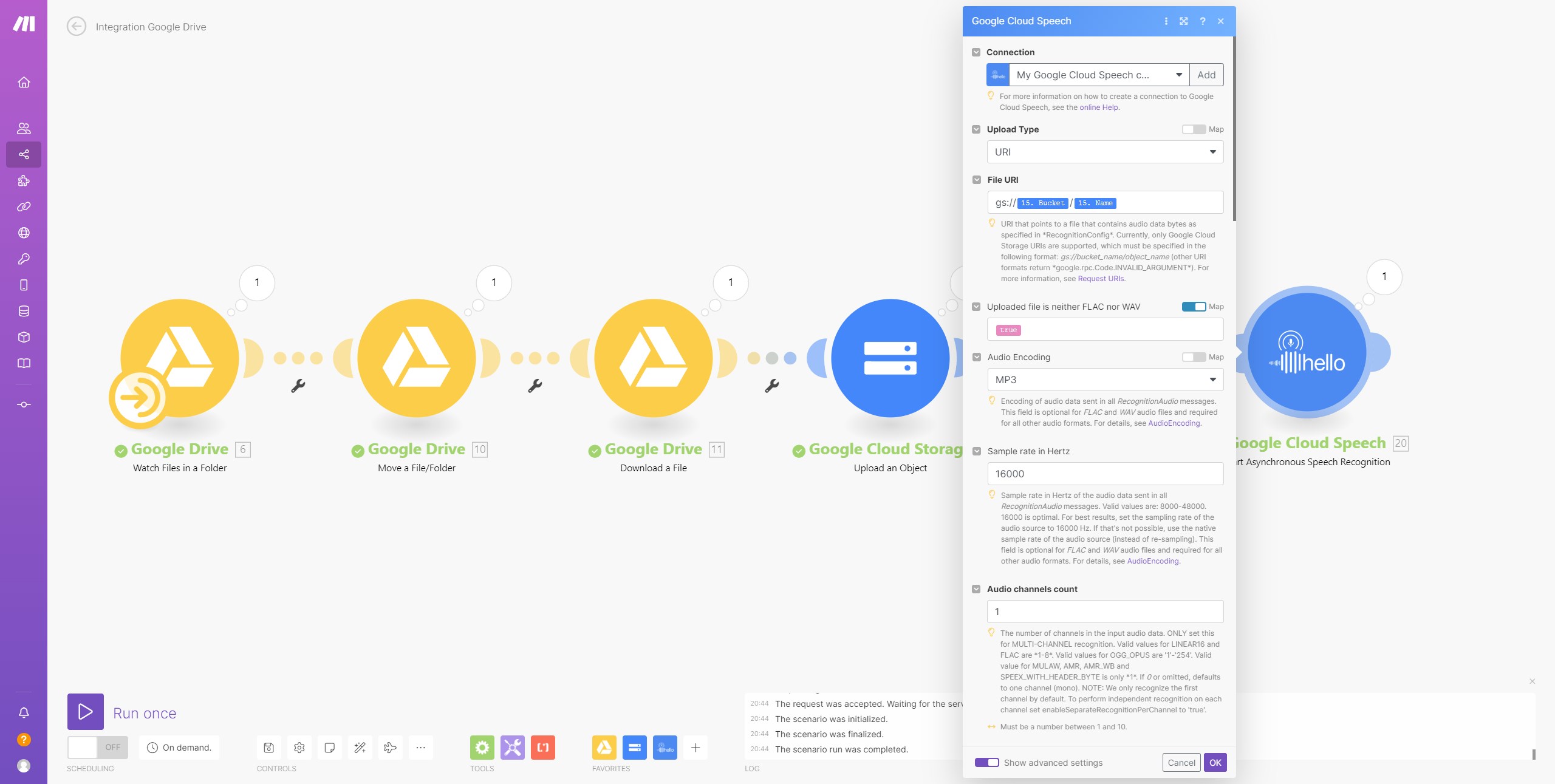
My workflow currently looks like this:
-
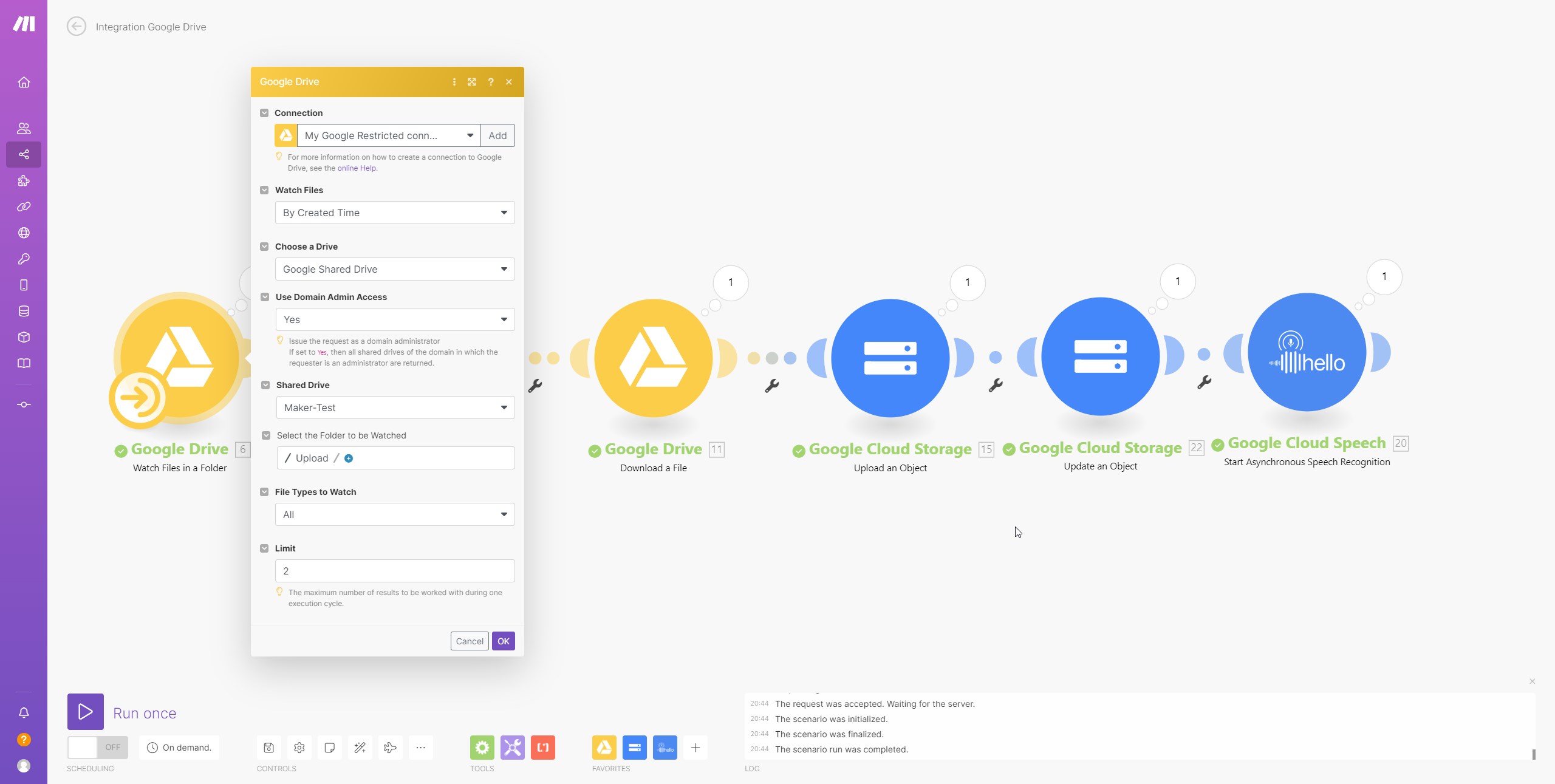
Google Drive: watch folder, for new mp3 files
-
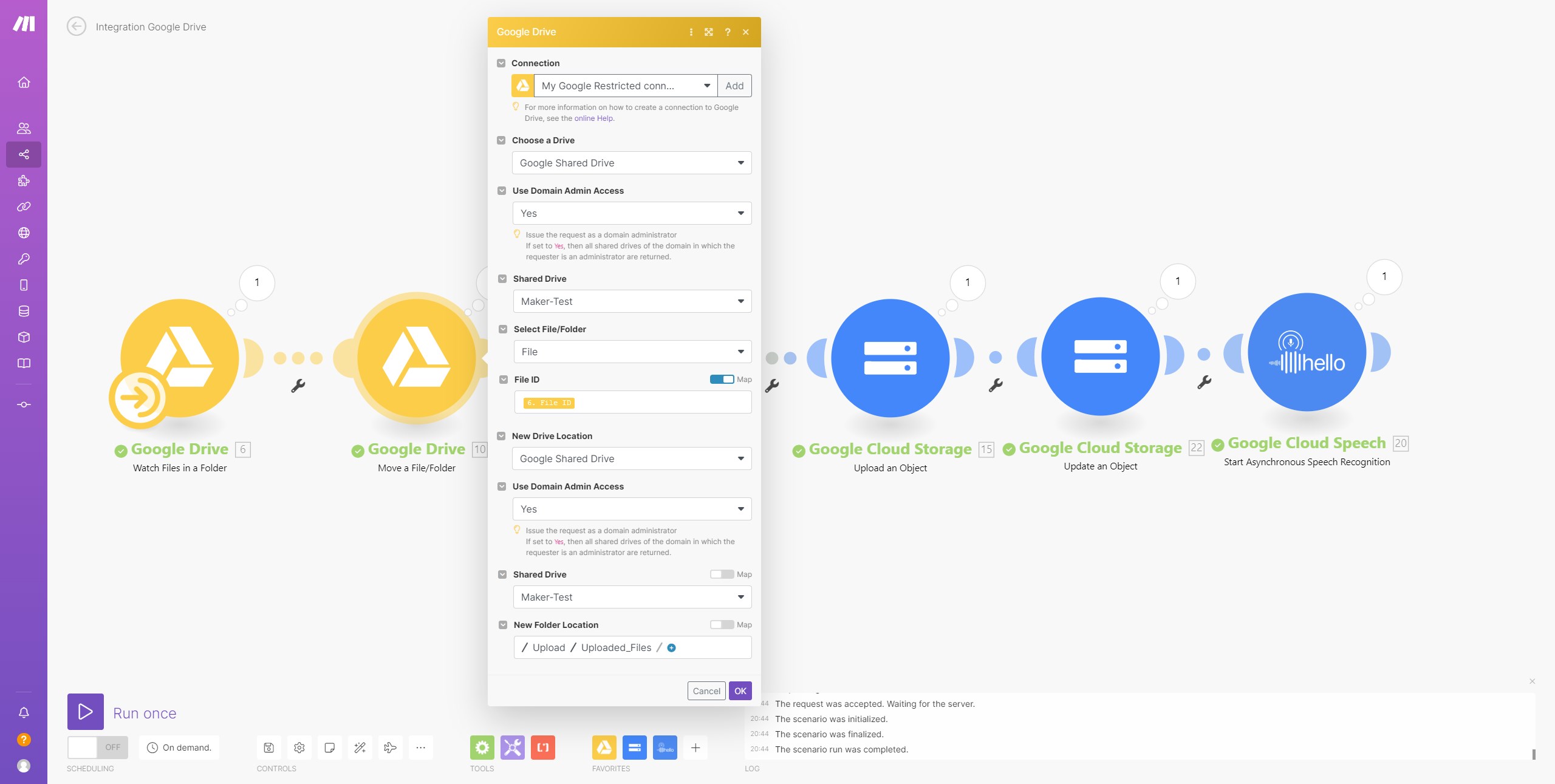
Google Drive: Move a File, to move the MP3 file to a subfolder, so I know which ones have been processed.
-
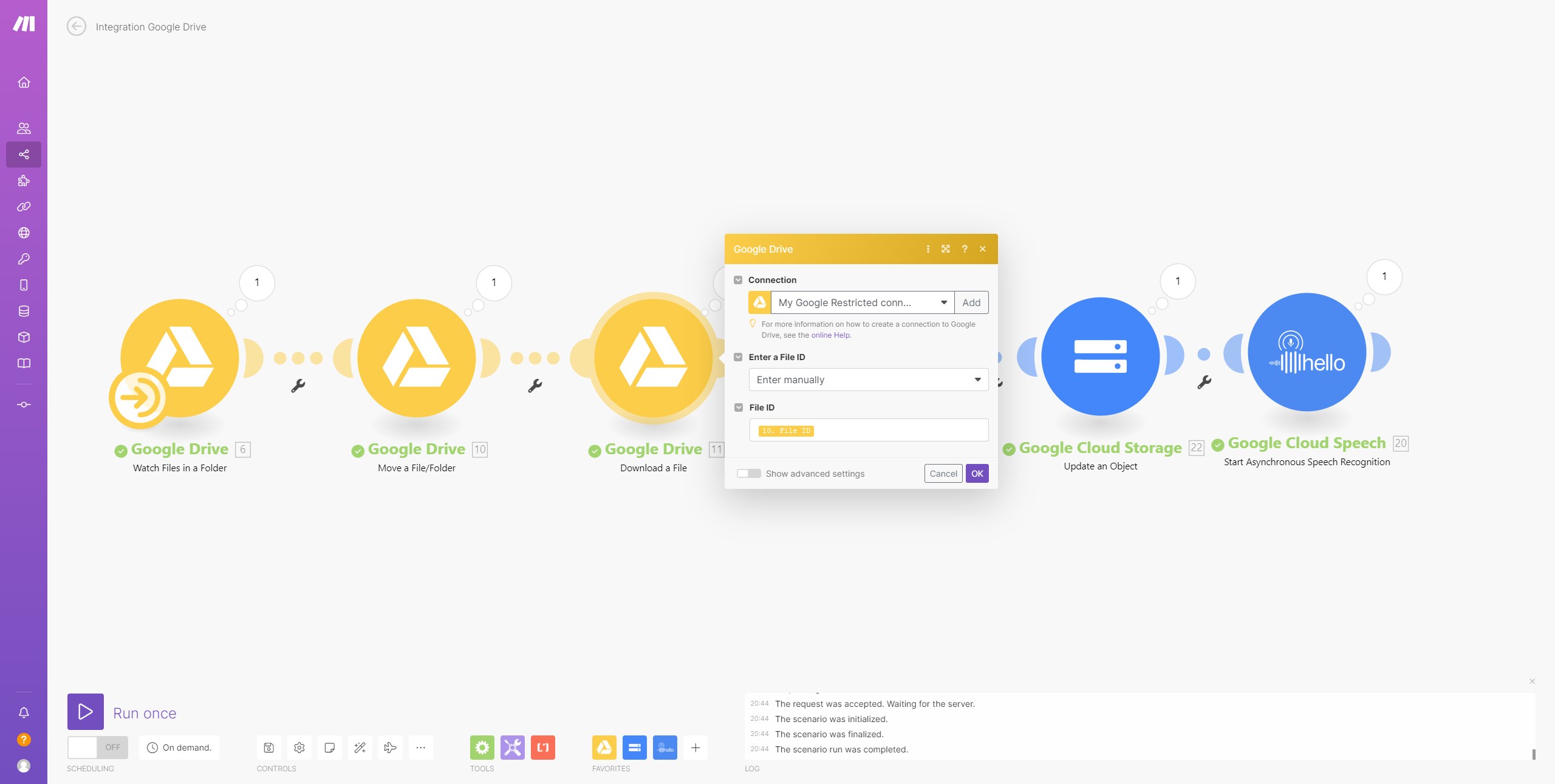
Google Drive: Download File, so I can use the MP3 file.
-
google cloud storage: Upload Object, the file will be uploaded to the cloud bucket.
Output
[
{
"kind": "storage#object",
"id": "syltfraeulein_speech/Loewenzahn_Kurz.mp3/1696272261434851",
"selfLink": "https://www.googleapis.com/storage/v1/b/syltfraeulein_speech/o/Loewenzahn_Kurz.mp3",
"mediaLink": "https://www.googleapis.com/download/storage/v1/b/syltfraeulein_speech/o/Loewenzahn_Kurz.mp3?generation=1696272261434851&alt=media",
"name": "Loewenzahn_Kurz.mp3",
"bucket": "syltfraeulein_speech",
"generation": "1696272261434851",
"metageneration": "1",
"contentType": "audio/mpeg",
"storageClass": "STANDARD",
"size": "2385375",
"md5Hash": "r8WoC7j2sodz8PDe/SKzxA==",
"crc32c": "uhEIkA==",
"etag": "COOb18yC2IEDEAE=",
"timeCreated": "2023-10-02T18:44:21.457Z",
"updated": "2023-10-02T18:44:21.457Z",
"timeStorageClassUpdated": "2023-10-02T18:44:21.457Z"
-
google cloud storage: Update Object to set the sharing of the file to public. (was just a test, in case Make.com does not have access).
-
Google Cloud Speech: Asynchronous Speech Recognition, to transcribe the MP3 file from the bucket into text.

I got this setting from this post: Google Cloud Speech-to-text module not working - #2 by Kirill_D
Input
[
{
"uri": "gs://syltfraeulein_speech/Loewenzahn_Kurz.mp3",
"encoding": "MP3",
"metadata": {
"interactionType": "VOICEMAIL",
"originalMimeType": "audio/mpeg",
"originalMediaType": "AUDIO",
"recordingDeviceType": "SMARTPHONE"
},
"FLACorWAV": true,
"uploadType": "uri",
"languageCode": "de-DE",
"sampleRateHertz": 16000,
"audioChannelCount": 1,
"enableSeparateRecognitionPerChannel": false
}
]
Output
[
{
"name": "791715767449740107"
}
]
Later with 7. the text should be saved in a Google Doc and the file will be deletet from the bucket, but I am not there yet.
Point 1-5 runs without problems.
At point 6, I then come to a problem. I pass the file to Cloud Speech via URI, but only get an output back that is not a transcription.
When I do the transcription with my test workflow, I end up with an output of
"alternatives": [
{
"transcript": "Here is the text",
"confidence": 0.90918183
}
This works only with audio recordings shorter than one minute but we want to have whole interviews transcribed.
Am I doing something wrong or do I think the workflow is too complicated?
Greetings ![]()